本篇文章转自:Some Techniques To Make Your PyTorch Models Train (Much) Faster
本篇博文概述了在不影响 PyTorch 模型准确性的情况下提高其训练性能的技术。为此,将 PyTorch 模型包装在 LightningModule 中,并使用 Trainer 类来实现各种训练优化。只需更改几行代码,就可以将单个 GPU 上的训练时间从 22.53 分钟缩短到 2.75 分钟,同时保持模型的预测准确性。
性能提升了 8 倍!
(本博文于 2023 年 3 月 17 日更新,现在使用 PyTorch 2.0 和 Lightning 2.0!)
实验汇总:
省流版(详细实验过程可参见下述实验训练记录):
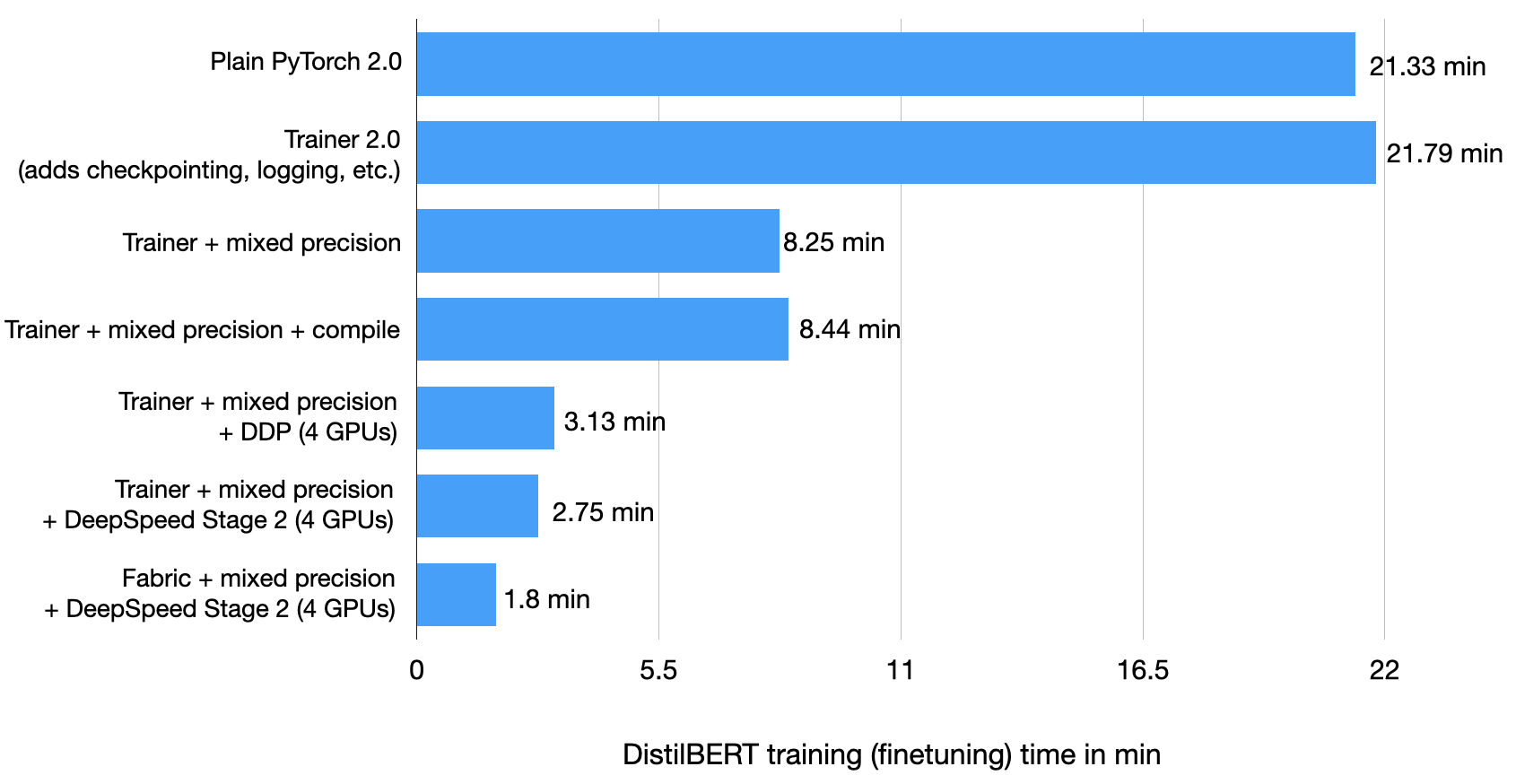
使用Pytorch与Pytorch Ligntning可以获得相同的训练时长(上图不一致在于加载checkpoint文件和log)
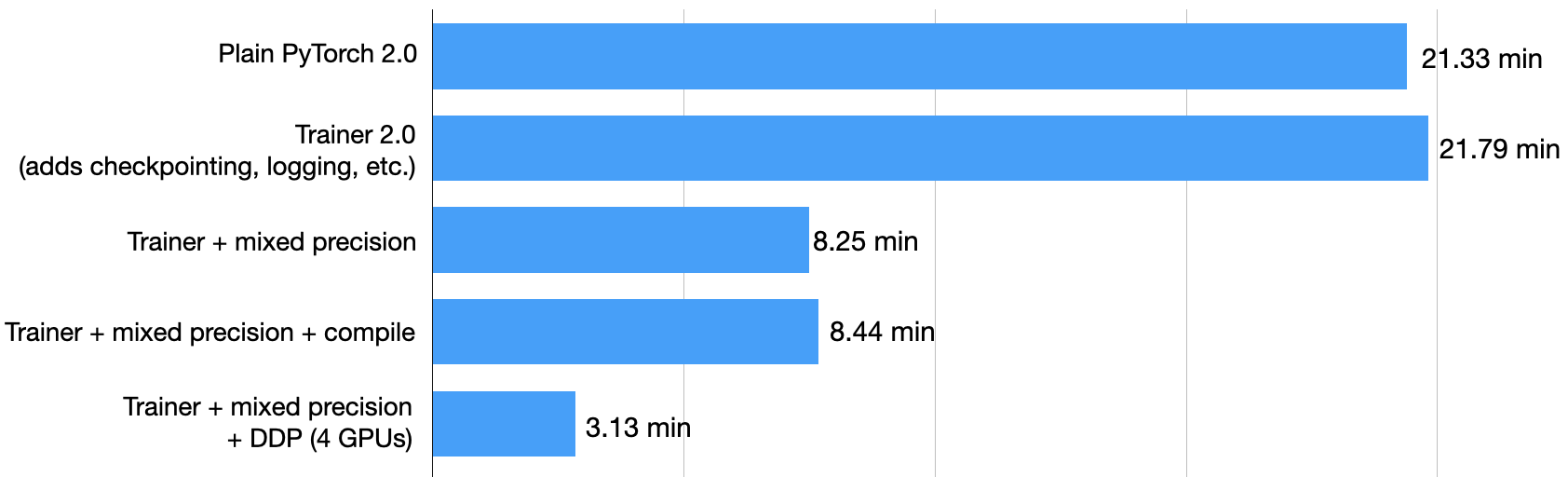
使用混合精度训练可将训练时间从 21.79 分钟缩短至 8.25 分钟!这几乎快了 3 倍!
测试集准确率为 93.2%——与之前的 92.6% 相比略有提高(可能是由于在不同精度模式之间切换时舍入引起的差异)。
在使用默认参数的情况下,似乎
torch.compile不会在混合精度环境中提高 DistilBERT 模型的性能。使用四块 A100 GPU,此代码运行时间为 3.07 分钟,测试准确率达到 93.1%
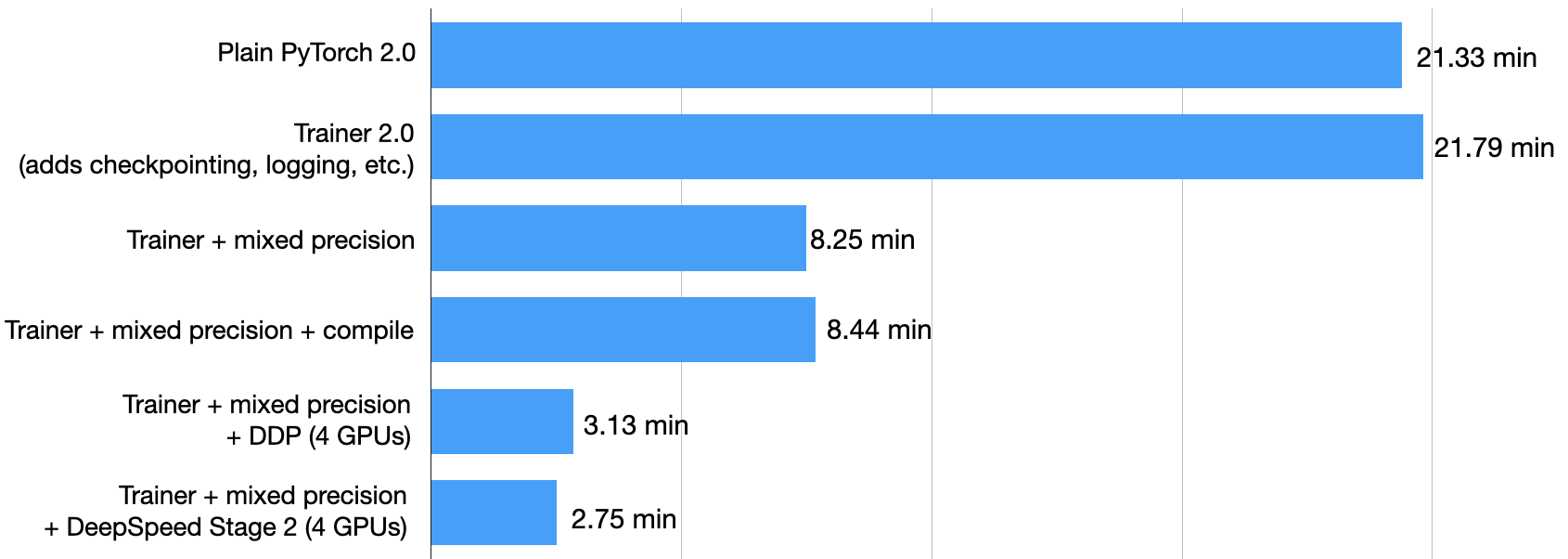
Trainer + 混合精度 + DeepSpeed + 多GPU运行花了 2.75 分钟
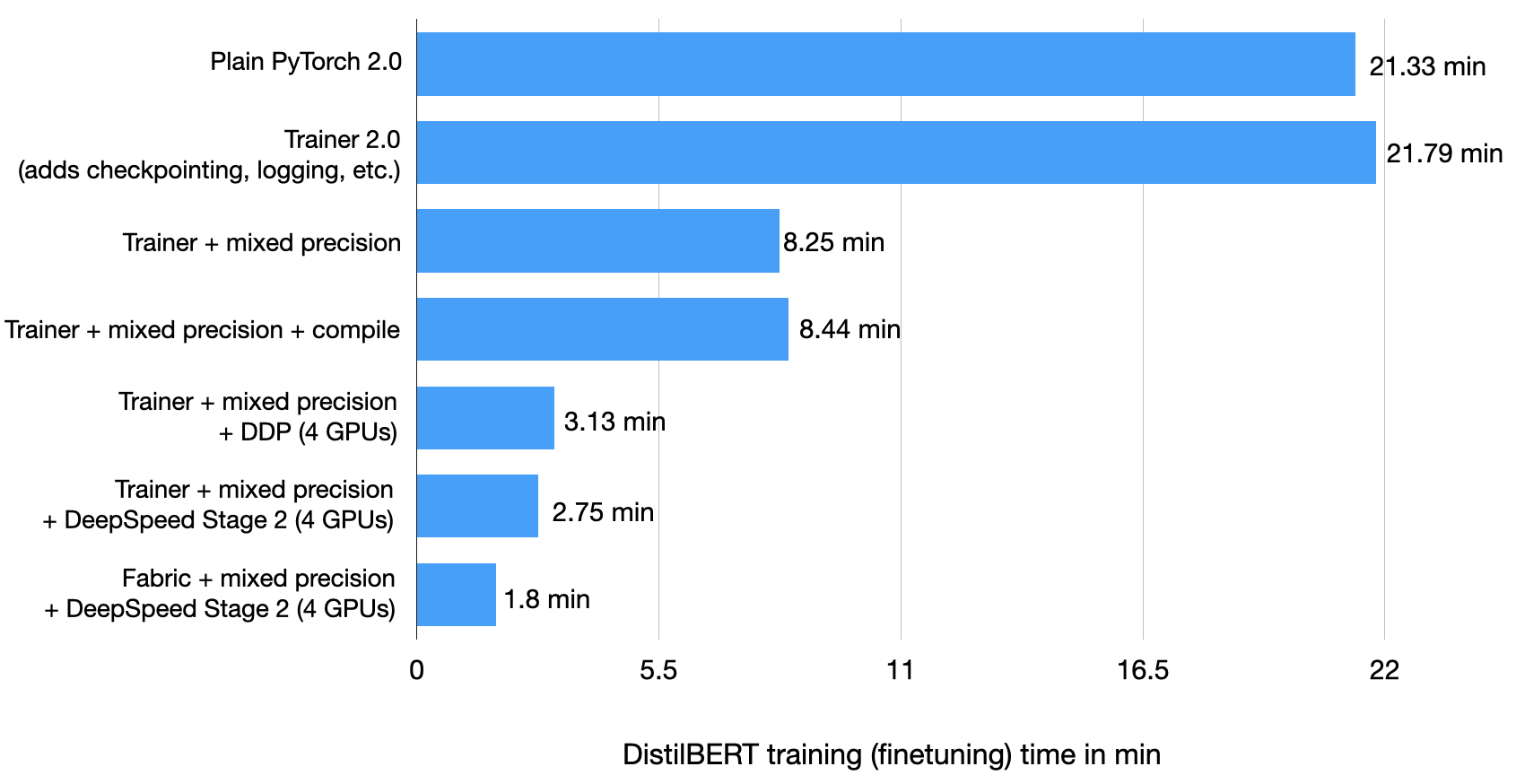
Fabric + 混合精度 + DeepSpeed + 多GPU运行花了 1.8 分钟
介绍
在本教程中,我们将微调DistilBERT 模型,这是 BERT 的精简版本,其规模缩小了 40%,但预测性能几乎相同。我们可以通过多种方式微调预训练语言模型。下图描述了三种最常见的方法。
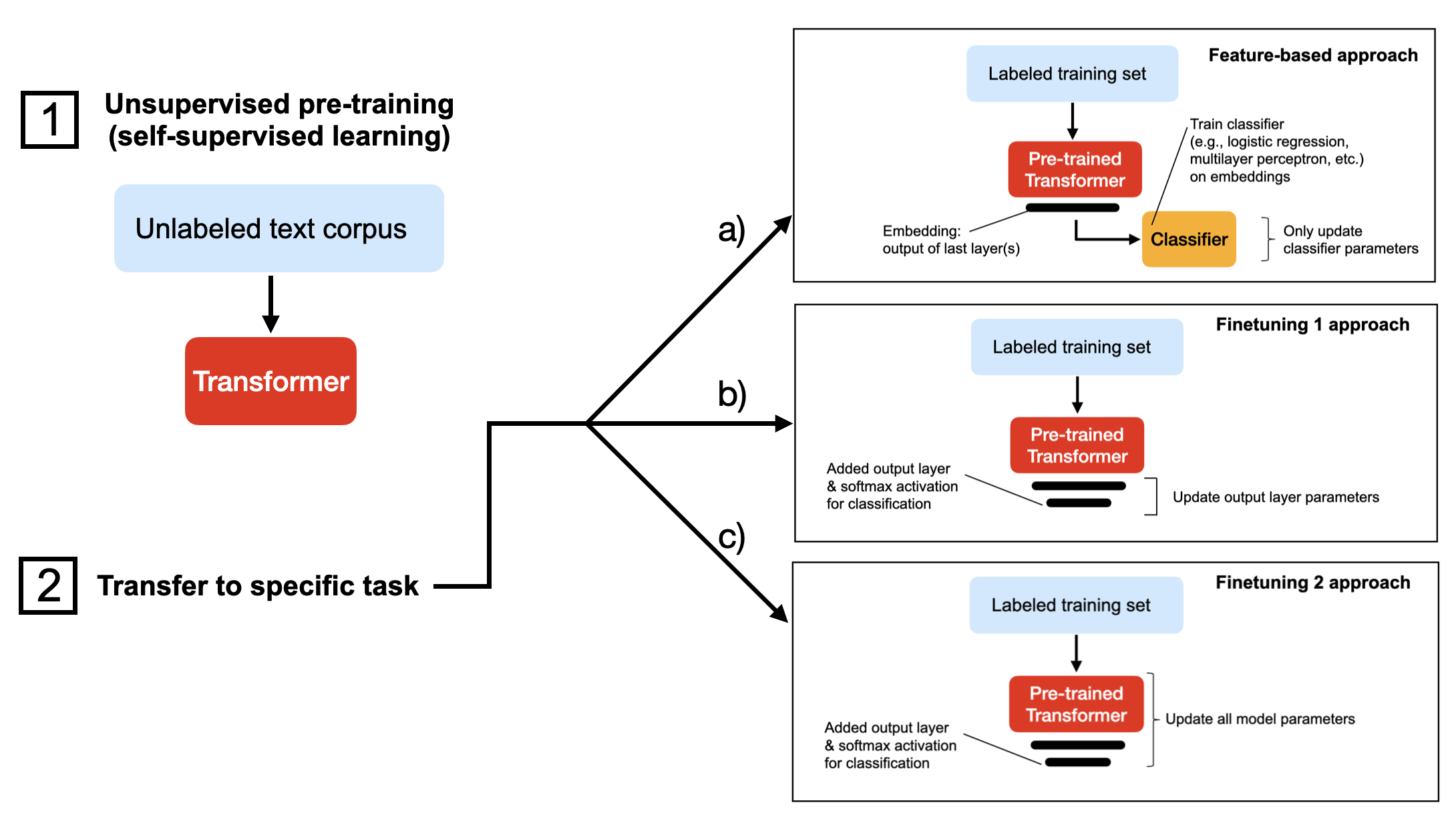
上述三种方法都假设我们已经使用自监督学习在未标记的数据集上对模型进行了预训练(步骤 1)。然后,在步骤 2 中,当我们将模型迁移到目标任务时,我们要么
- a)提取嵌入并在其上训练分类器(例如,可以是来自 scikit-learn 的支持向量机);
- b)替换/添加输出层并微调 Transformer 的最后一层(几层);
- c)替换/添加输出层并微调所有层。
方法 ac 按计算效率排序,其中 a) 通常是最快的。根据我的经验,这种排序顺序也反映了模型的预测性能,其中 c) 通常具有最高的预测准确率。
在本教程中,我们将使用方法 c) 并训练一个模型来预测总共包含 50,000 条电影评论的IMDB 大型电影评论数据集中的电影评论情绪。
1. 普通的 PyTorch 基线
作为热身练习,让我们从简单的 PyTorch 基线开始,在 IMDB 电影评论数据集上训练 DistilBERT 模型。如果您想自己运行代码,可以使用相关的 Python 库设置虚拟环境,如下所示:
conda create -n faster-blog python=3.9
conda activate faster-blog
pip install watermark transformers datasets torchmetrics lightning
作为参考,我使用的相关软件版本如下(当您在本文后面运行代码时它们将被打印到终端。):
Python version: 3.9.15
torch : 2.0.0+cu118
lightning : 2.0.0
transformers : 4.26.1
为了避免本文充斥着无聊的数据加载实用程序,我将跳过local_dataset_utilities.py文件,该文件包含用于加载数据集的代码。这里唯一相关的信息是我们将数据集划分为 35,000 个训练示例、5,000 个验证集记录和 10,000 个测试记录。
让我们来看看主要的 PyTorch 代码。除了我放在local_dataset_utilities.py文件中的数据集加载实用程序外,此代码是自包含的。在我们在下面讨论之前,请先查看 PyTorch 代码:
import os
import os.path as op
import time
from datasets import load_dataset
import torch
from torch.utils.data import DataLoader
import torchmetrics
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassification
from watermark import watermark
from local_dataset_utilities import (
download_dataset,
load_dataset_into_to_dataframe,
partition_dataset,
)
from local_dataset_utilities import IMDBDataset
def tokenize_text(batch):
return tokenizer(batch["text"], truncation=True, padding=True)
def train(num_epochs, model, optimizer, train_loader, val_loader, device):
for epoch in range(num_epochs):
train_acc = torchmetrics.Accuracy(task="multiclass", num_classes=2).to(device)
for batch_idx, batch in enumerate(train_loader):
model.train()
for s in ["input_ids", "attention_mask", "label"]:
batch[s] = batch[s].to(device)
### FORWARD AND BACK PROP
outputs = model(
batch["input_ids"],
attention_mask=batch["attention_mask"],
labels=batch["label"],
)
optimizer.zero_grad()
outputs["loss"].backward()
### UPDATE MODEL PARAMETERS
optimizer.step()
### LOGGING
if not batch_idx % 300:
print(
f"Epoch: {epoch+1:04d}/{num_epochs:04d} | Batch {batch_idx:04d}/{len(train_loader):04d} | Loss: {outputs['loss']:.4f}"
)
model.eval()
with torch.no_grad():
predicted_labels = torch.argmax(outputs["logits"], 1)
train_acc.update(predicted_labels, batch["label"])
### MORE LOGGING
with torch.no_grad():
model.eval()
val_acc = torchmetrics.Accuracy(task="multiclass", num_classes=2).to(device)
for batch in val_loader:
for s in ["input_ids", "attention_mask", "label"]:
batch[s] = batch[s].to(device)
outputs = model(
batch["input_ids"],
attention_mask=batch["attention_mask"],
labels=batch["label"],
)
predicted_labels = torch.argmax(outputs["logits"], 1)
val_acc.update(predicted_labels, batch["label"])
print(
f"Epoch: {epoch+1:04d}/{num_epochs:04d} | Train acc.: {train_acc.compute()*100:.2f}% | Val acc.: {val_acc.compute()*100:.2f}%"
)
print(watermark(packages="torch,lightning,transformers", python=True))
print("Torch CUDA available?", torch.cuda.is_available())
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch.manual_seed(123)
##########################
### 1 Loading the Dataset
##########################
download_dataset()
df = load_dataset_into_to_dataframe()
if not (op.exists("train.csv") and op.exists("val.csv") and op.exists("test.csv")):
partition_dataset(df)
imdb_dataset = load_dataset(
"csv",
data_files={
"train": "train.csv",
"validation": "val.csv",
"test": "test.csv",
},
)
#########################################
### 2 Tokenization and Numericalization
#########################################
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
print("Tokenizer input max length:", tokenizer.model_max_length, flush=True)
print("Tokenizer vocabulary size:", tokenizer.vocab_size, flush=True)
print("Tokenizing ...", flush=True)
imdb_tokenized = imdb_dataset.map(tokenize_text, batched=True, batch_size=None)
del imdb_dataset
imdb_tokenized.set_format("torch", columns=["input_ids", "attention_mask", "label"])
os.environ["TOKENIZERS_PARALLELISM"] = "false"
#########################################
### 3 Set Up DataLoaders
#########################################
train_dataset = IMDBDataset(imdb_tokenized, partition_key="train")
val_dataset = IMDBDataset(imdb_tokenized, partition_key="validation")
test_dataset = IMDBDataset(imdb_tokenized, partition_key="test")
train_loader = DataLoader(
dataset=train_dataset,
batch_size=12,
shuffle=True,
num_workers=1,
drop_last=True,
)
val_loader = DataLoader(
dataset=val_dataset,
batch_size=12,
num_workers=1,
drop_last=True,
)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=12,
num_workers=1,
drop_last=True,
)
#########################################
### 4 Initializing the Model
#########################################
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=2
)
model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=5e-5)
#########################################
### 5 Finetuning
#########################################
start = time.time()
train(
num_epochs=3,
model=model,
optimizer=optimizer,
train_loader=train_loader,
val_loader=val_loader,
device=device,
)
end = time.time()
elapsed = end - start
print(f"Time elapsed {elapsed/60:.2f} min")
with torch.no_grad():
model.eval()
test_acc = torchmetrics.Accuracy(task="multiclass", num_classes=2).to(device)
for batch in test_loader:
for s in ["input_ids", "attention_mask", "label"]:
batch[s] = batch[s].to(device)
outputs = model(
batch["input_ids"],
attention_mask=batch["attention_mask"],
labels=batch["label"],
)
predicted_labels = torch.argmax(outputs["logits"], 1)
test_acc.update(predicted_labels, batch["label"])
print(f"Test accuracy {test_acc.compute()*100:.2f}%")
(您也可以在 GitHub 上找到此代码:1_pytorch-distilbert.py。)
为了保持本文的重点,我将跳过 PyTorch 基础知识,重点描述此脚本的主要内容。但是,如果您是 PyTorch 新手,我建议您查看我的免费深度学习基础课程,我将在第 1-4 单元详细讲授 PyTorch。
上面的代码分为两部分,函数定义和在 下执行的代码if __name__ == "__main__"。
本部分的前三节if __name__ == "__main__"包含设置数据集加载器的代码。第四部分是初始化模型的地方:我们将对经过预训练的 DistilBERT 模型进行微调。然后,在第五部分中,我们运行训练函数并在测试集上评估经过微调的模型。
在 A100 GPU 上运行代码后,我得到了以下结果:
Epoch: 0001/0003 | Batch 0000/2916 | Loss: 0.6867
Epoch: 0001/0003 | Batch 0300/2916 | Loss: 0.3633
Epoch: 0001/0003 | Batch 0600/2916 | Loss: 0.4122
Epoch: 0001/0003 | Batch 0900/2916 | Loss: 0.3046
Epoch: 0001/0003 | Batch 1200/2916 | Loss: 0.3859
Epoch: 0001/0003 | Batch 1500/2916 | Loss: 0.4489
Epoch: 0001/0003 | Batch 1800/2916 | Loss: 0.5721
Epoch: 0001/0003 | Batch 2100/2916 | Loss: 0.6470
Epoch: 0001/0003 | Batch 2400/2916 | Loss: 0.3116
Epoch: 0001/0003 | Batch 2700/2916 | Loss: 0.2002
Epoch: 0001/0003 | Train acc.: 89.81% | Val acc.: 92.17%
Epoch: 0002/0003 | Batch 0000/2916 | Loss: 0.0935
Epoch: 0002/0003 | Batch 0300/2916 | Loss: 0.0674
Epoch: 0002/0003 | Batch 0600/2916 | Loss: 0.1279
Epoch: 0002/0003 | Batch 0900/2916 | Loss: 0.0686
Epoch: 0002/0003 | Batch 1200/2916 | Loss: 0.0104
Epoch: 0002/0003 | Batch 1500/2916 | Loss: 0.0888
Epoch: 0002/0003 | Batch 1800/2916 | Loss: 0.1151
Epoch: 0002/0003 | Batch 2100/2916 | Loss: 0.0648
Epoch: 0002/0003 | Batch 2400/2916 | Loss: 0.0656
Epoch: 0002/0003 | Batch 2700/2916 | Loss: 0.0354
Epoch: 0002/0003 | Train acc.: 95.02% | Val acc.: 92.09%
Epoch: 0003/0003 | Batch 0000/2916 | Loss: 0.0143
Epoch: 0003/0003 | Batch 0300/2916 | Loss: 0.0108
Epoch: 0003/0003 | Batch 0600/2916 | Loss: 0.0228
Epoch: 0003/0003 | Batch 0900/2916 | Loss: 0.0140
Epoch: 0003/0003 | Batch 1200/2916 | Loss: 0.0220
Epoch: 0003/0003 | Batch 1500/2916 | Loss: 0.0123
Epoch: 0003/0003 | Batch 1800/2916 | Loss: 0.0495
Epoch: 0003/0003 | Batch 2100/2916 | Loss: 0.0039
Epoch: 0003/0003 | Batch 2400/2916 | Loss: 0.0168
Epoch: 0003/0003 | Batch 2700/2916 | Loss: 0.1293
Epoch: 0003/0003 | Train acc.: 97.28% | Val acc.: 89.88%
Time elapsed 21.33 min
Test accuracy 89.92%
如上所示,模型从第 2 到第 3 个周期开始出现轻微过拟合,验证准确率从 92.09% 下降到 89.88%。最终测试准确率为 89.92%,这是我们在对模型进行 21.33 分钟的微调后达到的。
2)使用 Trainer 类
现在,让我们将 PyTorch 模型包装起来,LightningModule以便我们可以使用Trainer来自 Lightning 的类:
import os
import os.path as op
import time
from datasets import load_dataset
import lightning as L
from lightning.pytorch.callbacks import ModelCheckpoint
from lightning.pytorch.loggers import CSVLogger
import matplotlib.pyplot as plt
import pandas as pd
import torch
from torch.utils.data import DataLoader
import torchmetrics
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassification
from watermark import watermark
from local_dataset_utilities import (
download_dataset,
load_dataset_into_to_dataframe,
partition_dataset,
)
from local_dataset_utilities import IMDBDataset
def tokenize_text(batch):
return tokenizer(batch["text"], truncation=True, padding=True)
class LightningModel(L.LightningModule):
def __init__(self, model, learning_rate=5e-5):
super().__init__()
self.learning_rate = learning_rate
self.model = model
self.train_acc = torchmetrics.Accuracy(task="multiclass", num_classes=2)
self.val_acc = torchmetrics.Accuracy(task="multiclass", num_classes=2)
self.test_acc = torchmetrics.Accuracy(task="multiclass", num_classes=2)
def forward(self, input_ids, attention_mask, labels):
return self.model(input_ids, attention_mask=attention_mask, labels=labels)
def training_step(self, batch, batch_idx):
outputs = self(
batch["input_ids"],
attention_mask=batch["attention_mask"],
labels=batch["label"],
)
self.log("train_loss", outputs["loss"])
with torch.no_grad():
logits = outputs["logits"]
predicted_labels = torch.argmax(logits, 1)
self.train_acc(predicted_labels, batch["label"])
self.log("train_acc", self.train_acc, on_epoch=True, on_step=False)
return outputs["loss"] # this is passed to the optimizer for training
def validation_step(self, batch, batch_idx):
outputs = self(
batch["input_ids"],
attention_mask=batch["attention_mask"],
labels=batch["label"],
)
self.log("val_loss", outputs["loss"], prog_bar=True)
logits = outputs["logits"]
predicted_labels = torch.argmax(logits, 1)
self.val_acc(predicted_labels, batch["label"])
self.log("val_acc", self.val_acc, prog_bar=True)
def test_step(self, batch, batch_idx):
outputs = self(
batch["input_ids"],
attention_mask=batch["attention_mask"],
labels=batch["label"],
)
logits = outputs["logits"]
predicted_labels = torch.argmax(logits, 1)
self.test_acc(predicted_labels, batch["label"])
self.log("accuracy", self.test_acc, prog_bar=True)
def configure_optimizers(self):
optimizer = torch.optim.Adam(
self.trainer.model.parameters(), lr=self.learning_rate
)
return optimizer
if __name__ == "__main__":
print(watermark(packages="torch,lightning,transformers", python=True), flush=True)
print("Torch CUDA available?", torch.cuda.is_available(), flush=True)
torch.manual_seed(123)
##########################
### 1 Loading the Dataset
##########################
download_dataset()
df = load_dataset_into_to_dataframe()
if not (op.exists("train.csv") and op.exists("val.csv") and op.exists("test.csv")):
partition_dataset(df)
imdb_dataset = load_dataset(
"csv",
data_files={
"train": "train.csv",
"validation": "val.csv",
"test": "test.csv",
},
)
#########################################
### 2 Tokenization and Numericalization
########################################
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
print("Tokenizer input max length:", tokenizer.model_max_length, flush=True)
print("Tokenizer vocabulary size:", tokenizer.vocab_size, flush=True)
print("Tokenizing ...", flush=True)
imdb_tokenized = imdb_dataset.map(tokenize_text, batched=True, batch_size=None)
del imdb_dataset
imdb_tokenized.set_format("torch", columns=["input_ids", "attention_mask", "label"])
os.environ["TOKENIZERS_PARALLELISM"] = "false"
#########################################
### 3 Set Up DataLoaders
#########################################
train_dataset = IMDBDataset(imdb_tokenized, partition_key="train")
val_dataset = IMDBDataset(imdb_tokenized, partition_key="validation")
test_dataset = IMDBDataset(imdb_tokenized, partition_key="test")
train_loader = DataLoader(
dataset=train_dataset,
batch_size=12,
shuffle=True,
num_workers=1,
drop_last=True,
)
val_loader = DataLoader(
dataset=val_dataset,
batch_size=12,
num_workers=1,
drop_last=True,
)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=12,
num_workers=1,
drop_last=True,
)
#########################################
### 4 Initializing the Model
#########################################
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=2
)
#########################################
### 5 Finetuning
#########################################
lightning_model = LightningModel(model)
callbacks = [
ModelCheckpoint(save_top_k=1, mode="max", monitor="val_acc") # save top 1 model
]
logger = CSVLogger(save_dir="logs/", name="my-model")
trainer = L.Trainer(
max_epochs=3,
callbacks=callbacks,
accelerator="gpu",
devices=[1],
logger=logger,
log_every_n_steps=10,
deterministic=True,
)
start = time.time()
trainer.fit(
model=lightning_model,
train_dataloaders=train_loader,
val_dataloaders=val_loader,
)
end = time.time()
elapsed = end - start
print(f"Time elapsed {elapsed/60:.2f} min")
test_acc = trainer.test(lightning_model, dataloaders=test_loader, ckpt_path="best")
print(test_acc)
with open(op.join(trainer.logger.log_dir, "outputs.txt"), "w") as f:
f.write((f"Time elapsed {elapsed/60:.2f} min\n"))
f.write(f"Test acc: {test_acc}")
(您也可以在 GitHub 上找到此代码:2_pytorch-with-trainer.py。)
再次,我将跳过 的细节,LightningModule以便本文专注于性能方面。不过,我将在我的深度学习基础课程第 5 单元中更详细地介绍LightningModule和类,该课程将于 3 月推出。与此同时,我推荐官方 PyTorch Lightning 教程。Trainer
简而言之,我们设置了一个LightningModule定义如何执行训练、验证和测试步骤的类。然后,主要的变化是在代码第 5 部分,我们在这里微调模型。新变化是,我们现在将 PyTorch 模型包装在类中,LightningModel并使用该类Trainer来拟合模型:
#########################################
### 5 Finetuning
#########################################
lightning_model = LightningModel(model)
callbacks = [
ModelCheckpoint(save_top_k=1, mode="max", monitor="val_acc") # save top 1 model
]
logger = CSVLogger(save_dir="logs/", name="my-model")
trainer = L.Trainer(
max_epochs=3,
callbacks=callbacks,
accelerator="gpu",
devices=1,
logger=logger,
log_every_n_steps=10,
deterministic=True,
)
trainer.fit(
model=lightning_model,
train_dataloaders=train_loader,
val_dataloaders=val_loader,
)
由于我们之前注意到验证准确率从第 2 轮到第 3 轮有所下降,因此我们使用回调ModelCheckpoint来加载最佳模型(基于最高验证准确率)以在测试集上进行模型评估。此外,我们将性能记录到 CSV 文件中(我首选的记录保存方法),并将 PyTorch 行为设置为确定性。
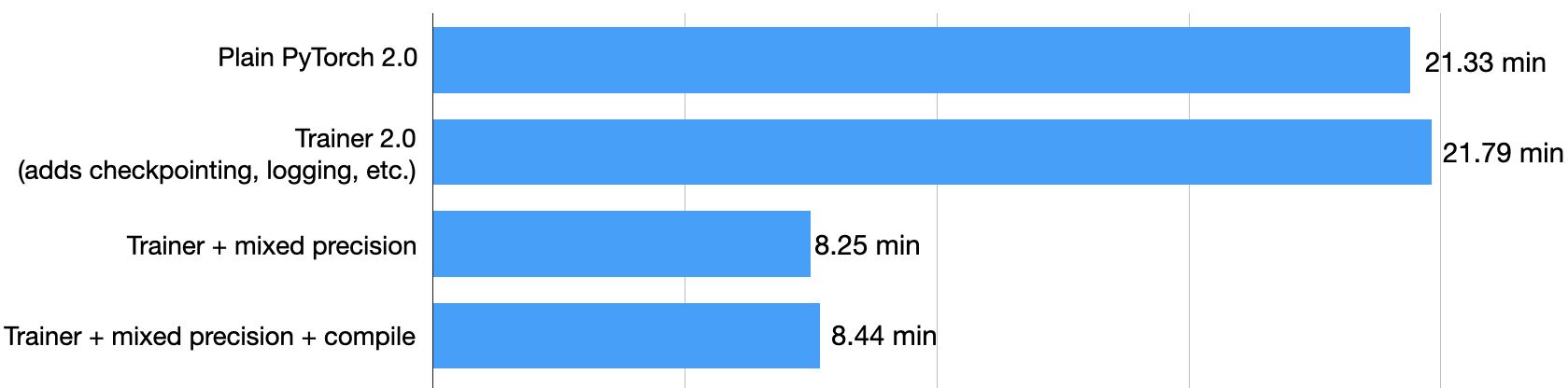
在同一台机器上,该模型在 21.79 分钟内达到了 92.6% 的测试准确率:
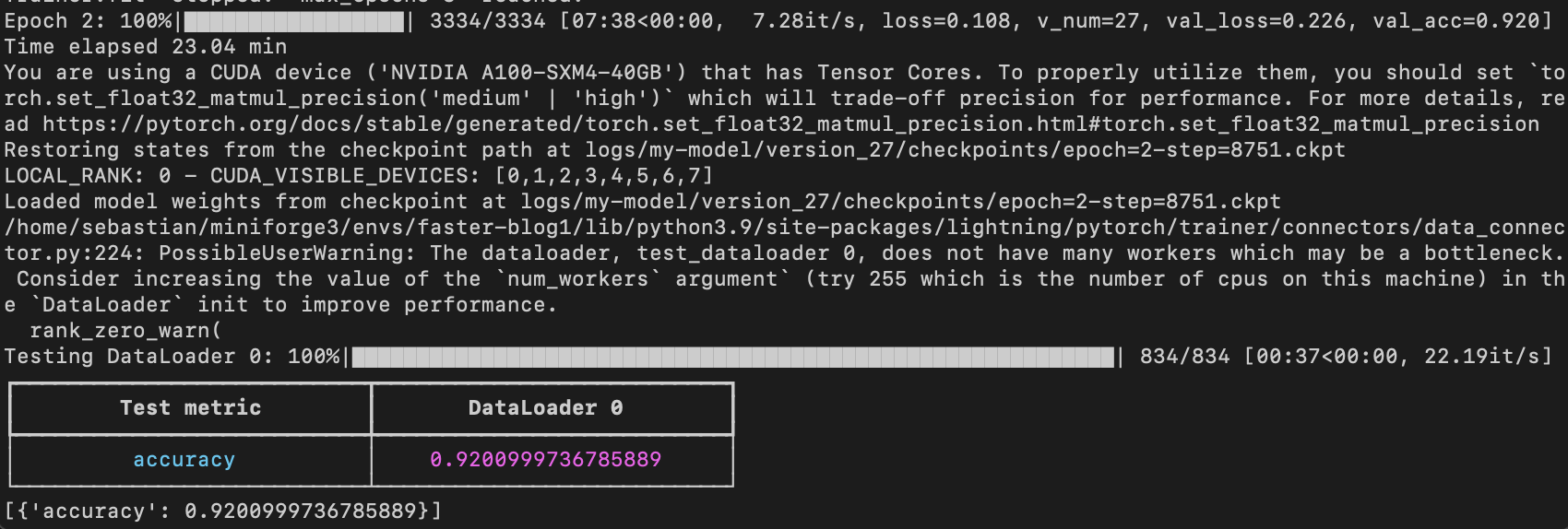
请注意,如果我们禁用检查点并允许 PyTorch 以非确定性模式运行,我们将获得与普通 PyTorch 相同的运行时间。

3)自动混合精度训练
如果我们的 GPU 支持混合精度训练,那么启用它通常是提高计算效率的主要方法之一。具体来说,我们使用自动混合精度训练,在训练期间在 32 位和 16 位浮点表示之间切换,而不会牺牲准确性。
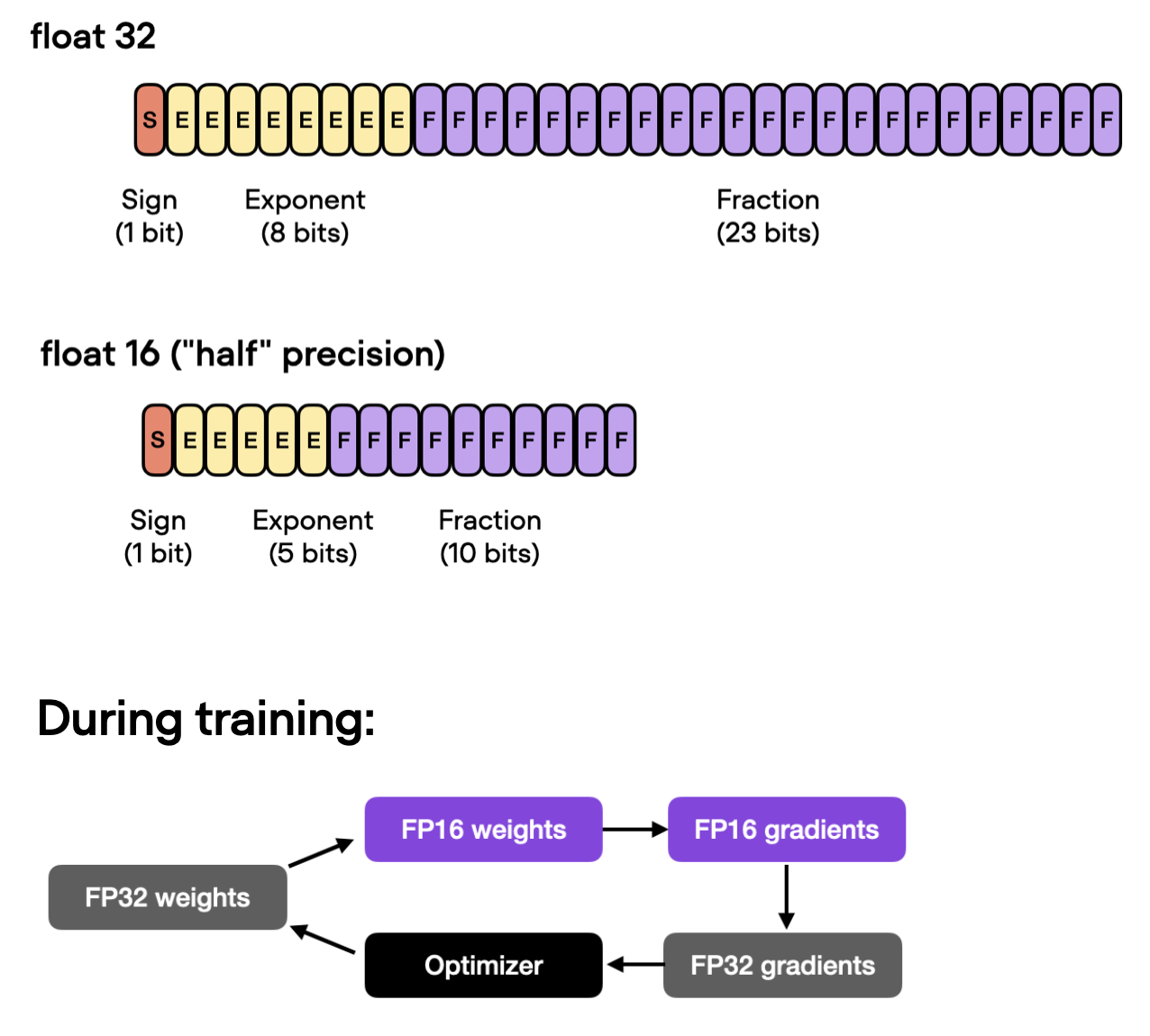
使用该类Trainer,我们可以用一行代码实现自动混合精度训练:
trainer = L.Trainer(
max_epochs=3,
callbacks=callbacks,
accelerator="gpu",
precision="fp16", # <-- NEW
devices=[1],
logger=logger,
log_every_n_steps=10,
deterministic=True,
)
如上所示,使用混合精度训练可将训练时间从 21.79 分钟缩短至 8.25 分钟!这几乎快了 3 倍!
测试集准确率为 93.2%——与之前的 92.6% 相比略有提高(可能是由于在不同精度模式之间切换时舍入引起的差异)。

4)使用 Torch.Compile 的静态图
在最近的 PyTorch 2.0 公告中,PyTorch 团队引入了新toch.compile功能,该功能可以通过生成优化的静态图而不是使用动态图(所谓的Eager模式)运行 PyTorch 代码来加速 PyTorch 代码的执行。在底层,这是一个三步过程,包括图获取、图降低和图编译。
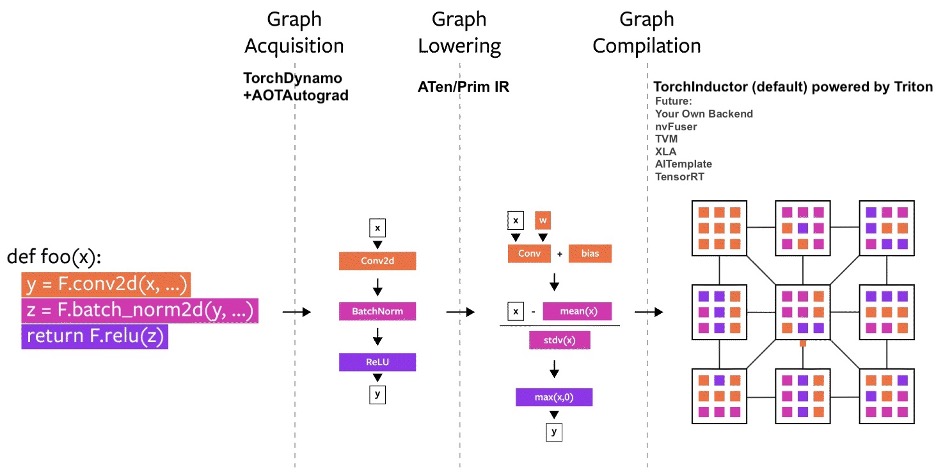
(图片来源:https://pytorch.org/get-started/pytorch-2.0/)
实现这一目标需要很多复杂的机制,PyTorch 2.0 公告中有更详细的解释。作为用户,我们可以通过一个简单的命令来使用这个新功能torch.compile。
为了利用torch.compile,我们可以通过添加这一行代码来修改我们的代码:
# ...
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=2
)
model = torch.compile(model) # NEW
lightning_model = LightningModel(model)
# ...
(有关该torch.compile函数的更多详细信息,还请参阅官方torch.compile 教程)
不幸的是,在使用默认参数的情况下,似乎torch.compile不会在混合精度环境中提高 DistilBERT 模型的性能。训练时间为 8.44 分钟,而之前为 8.25 分钟。因此,本教程中的后续基准测试将不会使用torch.compile。
旁注: 应用这两个技巧时,
- 将编译置于计时开始之前;
- 使用示例批次启动模型,如下所示
model.to(torch.device("cuda:0"))
model = torch.compile(model)
for batch_idx, batch in enumerate(train_loader):
model.train()
for s in ["input_ids", "attention_mask", "label"]:
batch[s] = batch[s].to(torch.device("cuda:0"))
break
outputs = model(
batch["input_ids"],
attention_mask=batch["attention_mask"],
labels=batch["label"],
)
lightning_model = LightningModel(model)
# start timing and training below
运行时间缩短至 5.6 分钟。这表明初始优化编译步骤需要几分钟,但最终会加速模型训练。在这种情况下,由于我们只训练模型三个时期,编译的好处由于额外的开销而不明显。但是,如果我们训练模型更长时间或训练更大的模型,编译将是值得的。
(警告:目前为分布式设置准备模型有点棘手,因为每个单独的 GPU 设备都需要模型的副本。它将需要一些代码重新设计,我可能会在以后重新审视,因此我不会在torch.compile下面的代码中使用。)
5)使用分布式数据并行在 4 个 GPU 上进行训练
在添加上述混合精度训练(并尝试添加图形编译)以加速单 GPU 上的代码之后,现在让我们探索多 GPU 策略。具体来说,我们现在将在四个 GPU 而不是一个 GPU 上运行相同的代码。
请注意,我在下图中总结了几种不同的多 GPU 训练技术。
为了使这篇博文重点突出、简洁明了,我建议你阅读我的《机器学习问答和人工智能》一书,了解有关不同多 GPU 训练范例的更多详细信息。该部分包含在免费预览版中。此外,我还将在我的深度学习基础课程第 9 单元中介绍这些内容,该课程计划于 4 月发布。
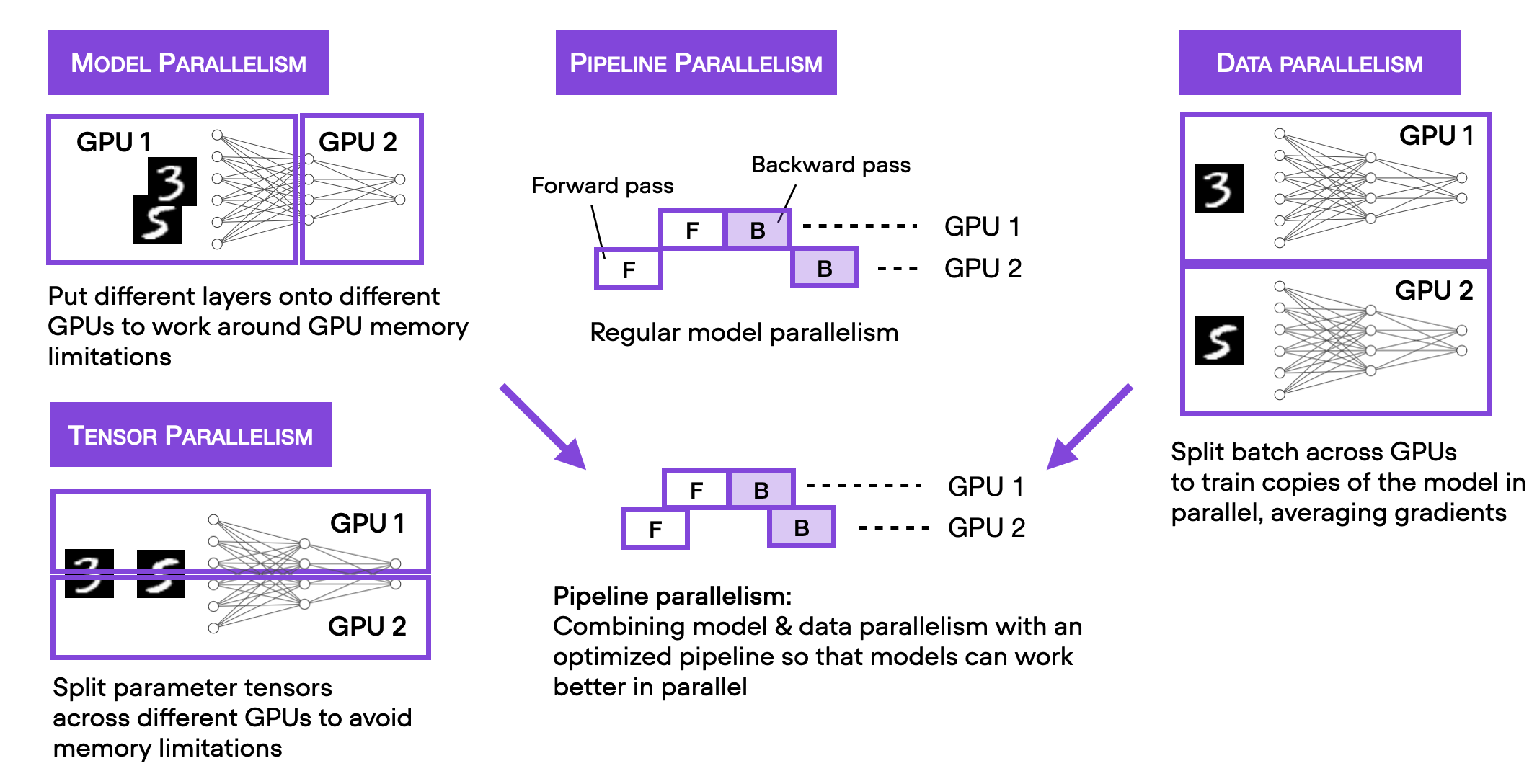
我们将从最简单的技术开始,即通过 实现数据并行DistributedDataParallel。使用Trainer,我们只需要修改一行代码:
trainer = L.Trainer(
max_epochs=3,
callbacks=callbacks,
accelerator="gpu",
devices=4, # <-- NEW
strategy="ddp", # <-- NEW
precision="16",
logger=logger,
log_every_n_steps=10,
deterministic=True,
)
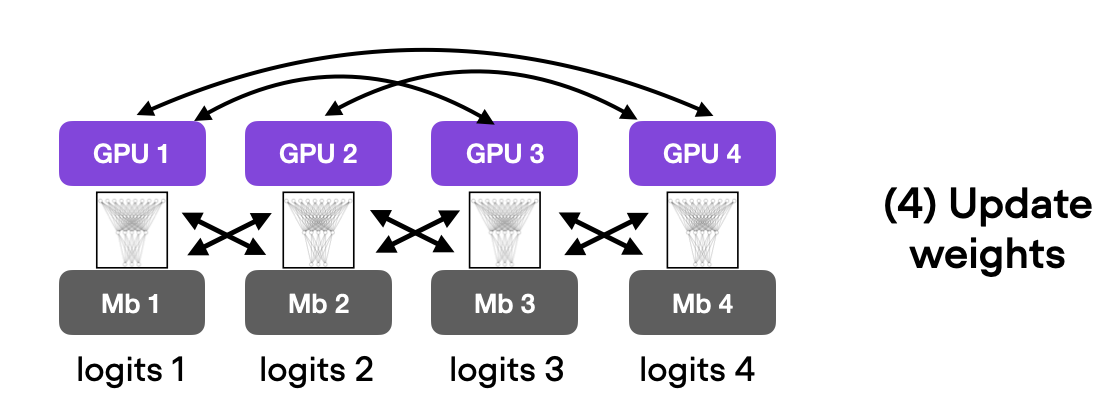
在我的计算机上,使用四块 A100 GPU,此代码运行时间为 3.07 分钟,测试准确率达到 93.1%。同样,测试集的改进很可能是由于使用数据并行时梯度平均。
(详细解释数据并行性是未来文章的另一个重要主题。)
6)DeepSpeed
最后,让我们探索一下可以在内部使用的DeepSpeedTrainer多 GPU 策略。
但在实际尝试之前,我想分享一下我的多 GPU 使用建议。使用哪种策略在很大程度上取决于模型、GPU 数量和 GPU 的内存大小。例如,在对大型模型进行预训练时,如果模型不适合单个 GPU,最好从简单的"ddp_sharded“”策略开始,该策略将张量并行性添加到"ddp"。使用前面的代码,"ddp_sharded"运行需要 2.58 分钟。
或者,我们也可以考虑更复杂的"deepspeed_stage_2"策略,将优化器状态和梯度分片。如果这不足以将模型放入 GPU 内存中,请尝试将优化器和梯度状态卸载到 CPU 内存(以性能为代价)的变体。您可以在官方ZeRO 教程"deepspeed_stage_2_offload"中找到有关 DeepSpeed 策略及其 ZeRO(零冗余优化器)的更多信息- 此外,有关卸载的更多信息,请参阅ZeRO 卸载教程。
回到建议,如果你想微调一个模型,计算吞吐量通常比将模型放入较少数量的 GPU 的内存中更重要。在这种情况下,你可以探索"stage_3"deepspeed 的变体,它将所有内容、优化器、梯度和参数分片,即
strategy="deepspeed_stage_3"strategy="deepspeed_stage_3_offload"
由于对于 DistilBERT 这样的小模型来说,GPU 内存不是问题,因此我们可以尝试一下"deepspeed_stage_2":
首先,我们必须安装 DeepSpeed Python 库:
pip install -U deepspeed
(在我的计算机上,安装了 deepspeed-0.8.2。)
接下来,我们"deepspeed_stage_2"只需更改一行代码即可启用:
trainer = L.Trainer(
max_epochs=3,
callbacks=callbacks,
accelerator="gpu",
devices=4,
strategy="deepspeed_stage_2", # <-- NEW
precision="16",
logger=logger,
log_every_n_steps=10,
deterministic=True,
)
这在我的计算机上运行花了 2.75 分钟,并实现了 92.6% 的测试准确率。
请注意,PyTorch 现在也有自己的 DeepSpeed 替代方案,称为完全分片 DataParallel,我们可以通过 使用它strategy="fsdp"。
7)Fabric
随着最近的 Lightning 2.0 版本发布,Lightning AI 发布了适用于 PyTorch 的新 Fabric 开源库。Fabric 本质上是扩展 PyTorch 代码的另一种方法,无需使用我在上面第 2) 节中介绍的 LightningModule和使用 Trainer 类。Trainer
Fabric 只需要更改几行代码,如下面的代码所示。-表示删除的行,+表示添加的行,用于将 Python 代码转换为使用 Fabric。
import os
import os.path as op
import time
+ from lightning import Fabric
from datasets import load_dataset
import matplotlib.pyplot as plt
import pandas as pd
import torch
from torch.utils.data import DataLoader
import torchmetrics
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassification
from watermark import watermark
from local_dataset_utilities import download_dataset, load_dataset_into_to_dataframe, partition_dataset
from local_dataset_utilities import IMDBDataset
def tokenize_text(batch):
return tokenizer(batch["text"], truncation=True, padding=True)
def plot_logs(log_dir):
metrics = pd.read_csv(op.join(log_dir, "metrics.csv"))
aggreg_metrics = []
agg_col = "epoch"
for i, dfg in metrics.groupby(agg_col):
agg = dict(dfg.mean())
agg[agg_col] = i
aggreg_metrics.append(agg)
df_metrics = pd.DataFrame(aggreg_metrics)
df_metrics[["train_loss", "val_loss"]].plot(
grid=True, legend=True, xlabel="Epoch", ylabel="Loss"
)
plt.savefig(op.join(log_dir, "loss.pdf"))
df_metrics[["train_acc", "val_acc"]].plot(
grid=True, legend=True, xlabel="Epoch", ylabel="Accuracy"
)
plt.savefig(op.join(log_dir, "acc.pdf"))
- def train(num_epochs, model, optimizer, train_loader, val_loader, device):
+ def train(num_epochs, model, optimizer, train_loader, val_loader, fabric):
for epoch in range(num_epochs):
- train_acc = torchmetrics.Accuracy(task="multiclass", num_classes=2).to(device)
+ train_acc = torchmetrics.Accuracy(task="multiclass", num_classes=2).to(fabric.device)
model.train()
for batch_idx, batch in enumerate(train_loader):
- for s in ["input_ids", "attention_mask", "label"]:
- batch[s] = batch[s].to(device)
outputs = model(batch["input_ids"], attention_mask=batch["attention_mask"], labels=batch["label"])
optimizer.zero_grad()
- outputs["loss"].backward()
+ fabric.backward(outputs["loss"])
### UPDATE MODEL PARAMETERS
optimizer.step()
### LOGGING
if not batch_idx % 300:
print(f"Epoch: {epoch+1:04d}/{num_epochs:04d} | Batch {batch_idx:04d}/{len(train_loader):04d} | Loss: {outputs['loss']:.4f}")
model.eval()
with torch.no_grad():
predicted_labels = torch.argmax(outputs["logits"], 1)
train_acc.update(predicted_labels, batch["label"])
### MORE LOGGING
model.eval()
with torch.no_grad():
- val_acc = torchmetrics.Accuracy(task="multiclass", num_classes=2).to(device)
+ val_acc = torchmetrics.Accuracy(task="multiclass", num_classes=2).to(fabric.device)
for batch in val_loader:
- for s in ["input_ids", "attention_mask", "label"]:
- batch[s] = batch[s].to(device)
outputs = model(batch["input_ids"], attention_mask=batch["attention_mask"], labels=batch["label"])
predicted_labels = torch.argmax(outputs["logits"], 1)
val_acc.update(predicted_labels, batch["label"])
print(f"Epoch: {epoch+1:04d}/{num_epochs:04d} | Train acc.: {train_acc.compute()*100:.2f}% | Val acc.: {val_acc.compute()*100:.2f}%")
train_acc.reset(), val_acc.reset()
if __name__ == "__main__":
print(watermark(packages="torch,lightning,transformers", python=True))
print("Torch CUDA available?", torch.cuda.is_available())
- device = "cuda" if torch.cuda.is_available() else "cpu"
torch.manual_seed(123)
##########################
### 1 Loading the Dataset
##########################
download_dataset()
df = load_dataset_into_to_dataframe()
if not (op.exists("train.csv") and op.exists("val.csv") and op.exists("test.csv")):
partition_dataset(df)
imdb_dataset = load_dataset(
"csv",
data_files={
"train": "train.csv",
"validation": "val.csv",
"test": "test.csv",
},
)
#########################################
### 2 Tokenization and Numericalization
#########################################
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
print("Tokenizer input max length:", tokenizer.model_max_length, flush=True)
print("Tokenizer vocabulary size:", tokenizer.vocab_size, flush=True)
print("Tokenizing ...", flush=True)
imdb_tokenized = imdb_dataset.map(tokenize_text, batched=True, batch_size=None)
del imdb_dataset
imdb_tokenized.set_format("torch", columns=["input_ids", "attention_mask", "label"])
os.environ["TOKENIZERS_PARALLELISM"] = "false"
#########################################
### 3 Set Up DataLoaders
#########################################
train_dataset = IMDBDataset(imdb_tokenized, partition_key="train")
val_dataset = IMDBDataset(imdb_tokenized, partition_key="validation")
test_dataset = IMDBDataset(imdb_tokenized, partition_key="test")
train_loader = DataLoader(
dataset=train_dataset,
batch_size=12,
shuffle=True,
num_workers=2,
drop_last=True,
)
val_loader = DataLoader(
dataset=val_dataset,
batch_size=12,
num_workers=2,
drop_last=True,
)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=12,
num_workers=2,
drop_last=True,
)
#########################################
### 4 Initializing the Model
#########################################
+ fabric = Fabric(accelerator="cuda", devices=4,
+ strategy="deepspeed_stage_2", precision="16-mixed")
+ fabric.launch()
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=2)
- model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=5e-5)
+ model, optimizer = fabric.setup(model, optimizer)
+ train_loader, val_loader, test_loader = fabric.setup_dataloaders(
+ train_loader, val_loader, test_loader)
#########################################
### 5 Finetuning
#########################################
start = time.time()
train(
num_epochs=3,
model=model,
optimizer=optimizer,
train_loader=train_loader,
val_loader=val_loader,
- device=device
+ fabric=fabric
)
end = time.time()
elapsed = end-start
print(f"Time elapsed {elapsed/60:.2f} min")
with torch.no_grad():
model.eval()
- test_acc = torchmetrics.Accuracy(task="multiclass", num_classes=2).to(device)
+ test_acc = torchmetrics.Accuracy(task="multiclass", num_classes=2).to(fabric.device)
for batch in test_loader:
- for s in ["input_ids", "attention_mask", "label"]:
- batch[s] = batch[s].to(device)
outputs = model(batch["input_ids"], attention_mask=batch["attention_mask"], labels=batch["label"])
predicted_labels = torch.argmax(outputs["logits"], 1)
test_acc.update(predicted_labels, batch["label"])
print(f"Test accuracy {test_acc.compute()*100:.2f}%")
我们可以看到,修改非常轻量!运行效果如何?Fabric 仅用 1.8 分钟就完成了微调!Fabric 比 Trainer 轻量一点——尽管它也能够使用回调和日志记录,但我们没有在这里启用这些功能,以便用一个极简示例来演示 Fabric。它的速度非常快,不是吗?
何时使用 Lightning Trainer 或 Fabric 取决于您的个人偏好。根据经验,如果您更喜欢现有 PyTorch 代码的轻量包装器,请查看 Fabric。另一方面,如果您转向更大的项目并更喜欢 Lightning 提供的代码组织,我推荐 Trainer。
结论
在本文中,我们探索了各种提高 PyTorch 模型训练速度的技术。如果我们使用 Lightning Trainer,我们可以用一行代码在这些选项之间切换,这非常方便——尤其是在调试代码时在 CPU 和 GPU 机器之间切换时。
我们尚未探索的另一个方面是最大化批处理大小,这可以进一步提高我们模型的吞吐量。不过,我们将把这个优化留到以后再讨论。
如果你想自己尝试这些代码,我已将它们全部分享到 GitHub 上





![[DataWhale大模型应用开发]学习笔记1-尝试搭建向量数据库](https://img-blog.csdnimg.cn/direct/210ca0716a7d4cce92102a7cf2be60a1.png#pic_center)